
搭建一个数据与价值之间的桥梁,实现数据安全跨域的融合,使数据在''可用不可见''的情况下完成数据价值的转化。
编辑 | 张核
2021年12月4日,科技智库「甲子光年」在线上举行了2021「甲子引力」大会。在当日下午举行的''企业服务''专场上,锘崴科技创始人、董事长王爽就''隐私保护计算赋能数据可信流动''为主题发表了演讲。
以下为王爽的演讲实录:
非常感谢甲子光年的邀请,我是来自杭州锘崴信息科技有限公司的王爽。锘崴科技的愿景是搭建一个数据与价值之间的桥梁,实现数据安全跨域的融合,使数据在''可用不可见''的情况下完成数据价值的转化。
首先,简单介绍一下数据隐私保护的相关背景。数据隐私保护的监管日趋完善,今年9月份实施的《数据安全法》和11月份实施的《个人信息保护法》都明确规定了对数据的分级分类、对数据敏感信息保护的刑事责任以及民事相关的行政责任。中国的法律其实跟国际法律进行对标的话会更加严格,比如《个人信息保护法》里面规定,如果数据造成泄露的话,罚款额度可以达到5000万人民币、5%的全球收入,比欧美GDPR4%还高1%,可见中国对整个数字隐私保护的重视程度。
对于数据隐私保护的需求也随之爆发。我们认为,整个数据隐私保护经历了三个阶段。1.0阶段是传统数据脱敏的阶段:通过把数据里面的敏感信息去掉,我们可以把脱敏后的数据交给第三方来使用。但这种模式下存在几个问题,第一是脱敏后的数据并不能保证数据的绝对安全。有很多研究发现,脱敏后的数据仍然能够进行个体的重新识别。比如去年锘崴科技和国家癌症中心共同完成的一项研究,研究范围包括20个省、100多家医院、7000多万病人。研究结果发现,基于国家标准或者国际标准完成脱敏后的数据,依然有0.01%的病人有被可识别的风险。另外,数据脱敏以后还是要交给第三方来使用的,所以数据的所有权、使用权和管理权无法有效分离,可能会存在数据转卖、滥用的风险,而根据最新的《个人信息保护法》里面''数据匿名化''的定义,不能回溯到个人信息的数据才是匿名化数据,脱敏后的数据还有可能会重新识别出来个体的,并没做到真正的''数据匿名化''。
2.0阶段是数据沙箱的模式:数据使用方可以在数据源指定的安全边界内完成数据相关的计算和分析,并获得结果,这就解决了数据使用权、管理权、所有权的确权问题。但引入了新的问题:目前,很多大数据研究、AI模型构建都需要非常丰富的数据维度以及极大的样本量,很难有一个公共的沙箱内同时汇聚各个医院、各个部委的数据来满足AI建模的需求,通常需要多个数据源进行合作。传统的解决方式是用不同的数据源构建不同的沙箱进行独立的计算,再通过统计的荟萃分析方法,把不同数据源的模型合并到一起,但这样的缺点是会引入计算误差,影响整个模型的精准度。
3.0阶段是隐私保护计算阶段:我们通过隐私保护计算这项技术,可以实现数据的虚拟融合,让数据在可用不可见的前提下完成多中心的联合分析,并且保证在虚拟融合下的数据分析结果和传统把数据汇总以后得到的结果是等价的。隐私保护计算技术其实是综合了多种底层技术的综合性解决方案,包括但不限于像联邦学习、可信计算环境、多方安全计算、同态加密这些技术,从而实现合规的数据价值流动。
任何系统都没有绝对的安全,任何安全都是建立在相关的假设条件下的。商业化的隐私保护计算解决方案其实要在满足应用场景的前提下尽可能做得更好,每项技术的适用范围、保护能力、性能、安全程度各有不同,所以就需要团队能够充分理解不同技术的性能。
我们认为隐私保护计算是一个系统化的体系,它首先要支持灵活的部署,可以支持一体机、容器化、云原生、弹性扩张、服务监控等多种架构,同时底层必须是一个非常强大的技术平台,可以支持不同的隐私保护计算技术,像联邦学习、可信计算环境、多方安全计算,服务于不同场景,像金融、政务、医疗等不同垂直应用,支持横向、纵向的数据分析模式。同时,它也要便于开发,可以提供第三方的开发接口,以及丰富的相关机器学习算法库,用以适配不同行业模型应用或者定制化开发的需求。同时,我们也需要得到足够的安全保证,因为隐私保护计算的基础是要保护数据的隐私,整个平台要满足安全体系架构最好的设计原则,满足相关的认证。
简单介绍一下锘崴科技的产品和服务。
我们的核心产品是大数据隐私保护的底层平台,平台上可以支持不同领域的垂直深度应用,像医疗、金融、政务、安防等不同领域。
锘崴科技在联邦学习、可信计算环境、密码学的同态加密、多方安全计算等相关的细分领域里面都有开创性的工作。比如说在联邦学习领域,我们团队在2012年的时候首次在全球提出了在线联邦学习的框架,谷歌在2016年——晚了我们四年以后——才把联邦学习构架应用到移动互联网。在可信计算环境领域,我们是全球第一批和英特尔合作、通过可信计算环境来支持跨国多中心的研究的团队。在同态加密领域,我们在2017年牵头,和国际化组织ISO、美国NIST一起建立国际同态加密相关的安全以及应用的标准。而且,我们在2016年就把多方安全计算和联邦学习的技术结合起来,服务于多中心医疗网络下的数据分析。
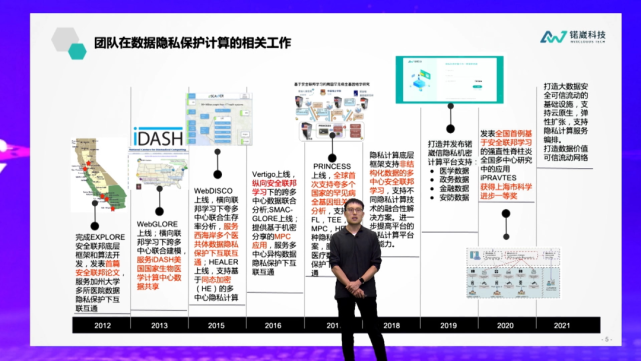
我们整个团队在隐私保护计算领域有300多篇相关论文,总的引用量有22000次,之前获得的自然科学基金的资助也有数亿元。我们团队也是iDASH——目前最大规模的全球隐私保护计算大赛——的创始人,这个竞赛是我在2014年创办的,至今已经举办了八年,每年大概有19个国家的100多个队伍会参与到比赛里面,参赛者包括IBM、微软、英特尔、BAT,以及MIT、斯坦福等高校的队伍。除此之外,我们公司也获得了国际化组织、工信部、公安部相关的认证,同时我们所有的产品也完成了信创的适配。
从产品形式来讲,我们有非常丰富的产品形式,我们可以支持不同类型的数据,像政务数据、金融里面的工商数据、医疗数据等,我们可以通过区块链实现数据使用全流程过程当中的溯源和监管。我们还提供软硬件一体机,用户把一体机接入到数据源后就可以对外提供带有隐私保护计算能力的服务,或者如果用户已经有基础设施,我们可以通过软件包或者虚拟化的形式进行产品部署,而如果用户数据本身在云上,我们可以提供云原生的SaaS服务。
从产品能力来讲,我们提供完整、全套的隐私保护计算能力,包括但不限于隐私查询、多中心隐私建模分析、推理等相关服务。数据使用的全流程是加密的,使用者可以在可控的情况下完成数据的共享,同时数据在整个使用过程当中是可追溯的。
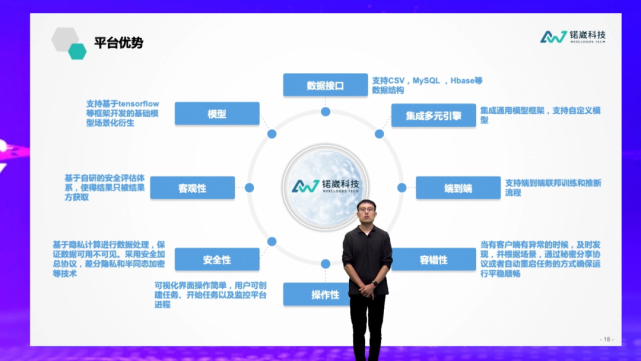
简单介绍一下锘崴科技产品的几个应用场景。
第一个应用场景,多中心联合分析建模推理。在这个场景下,有多个中心要进行合作,每个中心可能有不同维度的数据,或者来自不同个体的数据,通过多中心的合作,我们可以有效提高模型的样本量或者维度的丰富程度,实现更精准的客户画像。但由于不同机构里面商业利益冲突或者法律的要求,他们没有办法直接进行数据的共享。通过隐私保护计算这项技术,就可以结合多个数据源完成多中心联合的数据分析,提供更精准的模型,应用于不同的应用场景。
同时,我们还提供多中心的目标匹配以及隐私查询,比如说黑名单、白名单的匹配,在这个模式下,每个中心可能都有不同的数据库。在黑名单白名单的匹配过程当中,各方都不想把自己的查询条件、匹配模型和被查询的数据源泄露给第三方。我们通过隐私保护计算这项技术,可以以加密的查询条件去匹配加密的数据源情况,生成加密的结果,这个加密的结果可以定向发给最终的用户,完成带有保护隐私情况下的查询。
具体的几个案例,比如说在金融领域,我们跟某省级数据交易中心合作,实现了跨多个中心的普惠金融的应用。省一级的数据交易中心可以收集到了像工商、税务、环保等相关企业公共信息,银行通过这些公共信息可以实现更精准的普惠金融贷款发放,同时提供普惠金融风控的相关服务。但是这些部委的数据是没有办法直接交给银行的,银行对于某些企业流水的信息也没有办法直接交给数据交易中心,通过隐私保护计算的技术,我们可以在多中心互相不泄露自己数据的情况下完成精准的模型构建,通过补全不同维度的信息实现更精准的普惠金融放贷、风控等相关应用。
另一个金融场景,是我们跟一些头部保险公司的合作,我们通过AI结合多个外部数据源实现更精准的保险营销以及保险相关核保的应用。保险公司可以通过自有的数据源触达到移动运营商的数据、体检中心的数据和银联的数据,在用户授权的前提下,通过隐私保护计算技术不需要分享数据就可以完成多中心的建模,实现精准的营销,帮助保险公司提高50-80%的客户转化率。
在安防领域,我们跟公安部合作,通过用实时的捕捉人脸相关信息跟相关嫌疑犯数据库进行比对,来做安防相关的工作。传统模式下,这些捕获到的信息会以明文的形式存留在相关服务器上,带来潜在的个人信息泄露风险,也没有办法满足《数据安全法》和《个人信息保护法》里面规定的''最小收集原则''和''个人信息处理所需的最短保存期限原则''。通过隐私保护计算技术,我们可以实现在捕捉的过程当中全流程人像数据的加密,只有在对比时嫌疑犯的可能性达到某一个阈值的前提下,我们才会把明文人像信息解密出来交给公共机关,来去做相关的事后处理,这样我们就可以实现数据''最小收集原则''和''个人信息处理所需的最短保存期限原则''的法律要求。
同时,我们在医学领域也开发了很多应用,我们跟上海长征医院、清华大学、四川华西医院、安徽郑州几所大学实现了跨多省的多中心全基因组关联分析研究,服务于风湿免疫疾病里面的强直性脊柱炎的研究。通过合作,我们支持了3000多个病人、每个个体300多G的基因组学数据的分析,在分析过程当中,每个数据源的个体数据无需出其管理边界,这项研究成果也获得了上海市科学进步一等奖,并刊发在顶级生物医学期刊。此外,我们也跟中华医学会下面的消化外科一起合作,通过隐私保护计算来服务消化外科癌症全国数据库的构建,以及基于这个数据库的科研项目。目前,数据库已经支持了跨24个省、60多家的三甲医院数据在隐私保护情况下的互联互通。
今天就跟大家交流这些,非常感谢大家的时间,也希望有机会能够跟大家进一步的交流,谢谢大家!
 TNT系统办公娱乐两不误 坚果Pro 3 最低2399
TNT系统办公娱乐两不误 坚果Pro 3 最低2399 支付宝的自研金融级分布式关系数据库OceanB
支付宝的自研金融级分布式关系数据库OceanB