前言
前段时间在做数据碰撞分析时,遇到一个在数亿级的int型数据集中查找30万个特定int值是否存在的需求,当时尝试了几种方式
通过分片,然后做增量分析HashMap这两种方式第一种太慢,即使后面进一步实现了分布式计算,可仍然无法接受;第二种直接写爆内存。
后续经过探索尝试,通过字典查找树、布隆过滤都可以高效的实现上述需求,接下来分别分享下两种方式的具体实现。
字典查找树简介
Trie树,即字典树,又称单词查找树或键树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计和排序大量的字符串,所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。
基本特性
根节点不包含字符,除根节点外每一个节点都只包含一个字符。从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。每个节点的所有子节点包含的字符都不相同。通过这三个基本性质,我们不难发现Trie的核心思想是空间换时间,利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。对于庞大的空间消耗,我们可以用链表来动态开辟空间,达到空间上利用率的最大化。
代码实现
具体源码分享,详见我分享的另一篇文章——《Python实现大数据集下高效查询、联想、统计的数据结构——Tire树》
我们看下字典查找树是记录数据的结构,下面是我们将19825011312, 19825029527
两个手机号码添加到树中。

那么它的性能如何?使用profile对TrieTree算法进行性能测试,具体测试结果数据不贴了,说下结论。
500万条17位数字字符串添加,单次执行微秒级。500万数据集中查询某特定元素是否存在,微妙级500万数据集中通过某特定前缀字符串联想其他元素,毫秒级布隆过滤简介
Burton Howard Bloom 在 1970 年提出了一个叫做 Bloom Filter(中文翻译:布隆过滤)的算法。它主要就是用于解决判断一个元素是否在一个集合中,但它的优势是只需要占用很小的内存空间以及有着高效的查询效率。官方的说法是:它是一个保存了很长的二级制向量,同时结合 Hash 函数实现的。
基本特性
属于概率数据结构,只要返回数据不存在,则肯定不存在,返回数据存在,但只能是大概率存在。无法删除其中的元素。无法返回元素本身
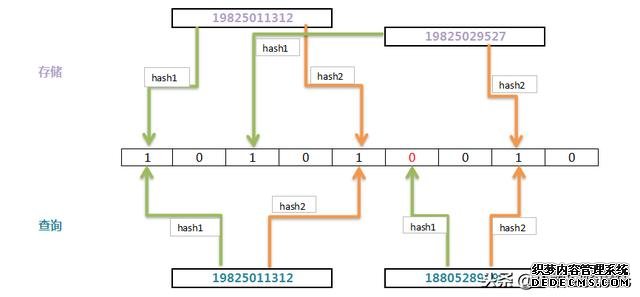
特性原理介绍,如图所示:
首先需要初始化一个二进制的数组,长度设为 L(图中栗子为 9),同时初始值全为 0 。当写入一个 N1=19825011312的数据时,需要进行K次 hash 函数的运算(栗子中进行了2 次);与 HashMap 有点类似,通过算出的 HashCode 与 L 取模后定位到 0、4 处,将该处的值设为 1。N2=19825029527也是同理计算后将 2、7 位置设为 1。当有一个N3=19825011312需要判断是否存在时,也是做同样两次 Hash 运算,定位到 0、4 处,此时他们的值都为 1 ,所以认为N3=1000 存在于集合中。当有一个 N4=18805289099时,也是同理。也是做同样两次 Hash 运算,定位到5、7处,可5处的值为 0,所以认为 N4不存在于集合中。总结讲起来就是:
对写入的数据做 K次 hash 运算定位到数组中的位置,同时将数据改为 1 。当有数据查询时也是同样的方式定位到数组中。 若其中的有一次计算hash计算结果所定位的数字为 0 则认为数据肯定不存在于集合,否则数据可能存在于集合中。
代码实现
python 安装
pip install pybloom模式一 BloomFilter 定容
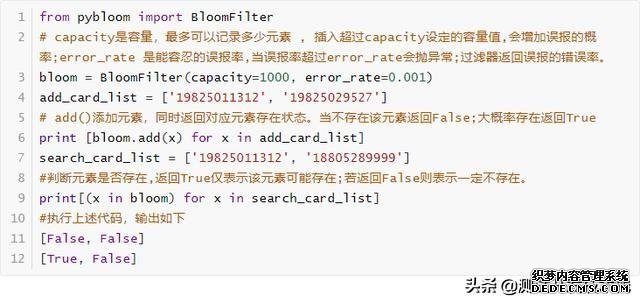
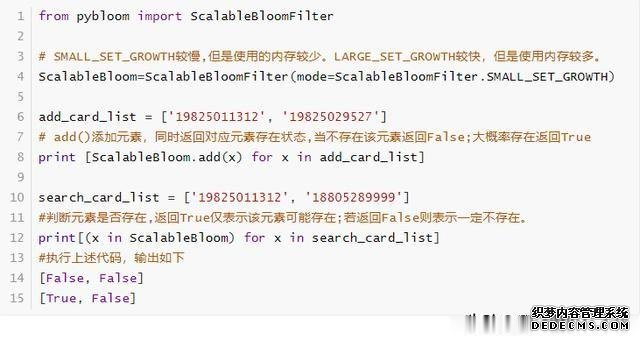
模式二 ScalableBloomFilter 可以自动扩容
欢迎转载,若对你有帮助,点赞支持哦。
 联通大数据:场景是金融大数据价值主秀场曹
联通大数据:场景是金融大数据价值主秀场曹 浙江绍兴:上虞“三色”预警通过国标验收
浙江绍兴:上虞“三色”预警通过国标验收